Atrinet Tech Blog Series.
ServiceNow CMDB Health & Governance
(1 of 2)
Situation
You’ve got ServiceNow running. Discovery is humming. Incidents are flowing. Changes are happening. Everything looks operational.
Then someone decommissions a server, and three business-critical services go dark because nobody knew about the dependencies. Or Security asks for a list of Windows 2012 servers, and the CMDB returns 847 records – 300 are duplicates, 150 are decommissioned but still active, and 200 haven’t been updated in 18 months.
Your CMDB isn’t just messy. It’s actively lying to you.
Common Approach
Most teams treat CMDB health as a “we’ll clean it up later” problem.
Run Discovery and assume the data is good. Manually spot-check CIs when something breaks. Assign someone to dedupe quarterly. Hope people update ownership during incidents.
The mindset: Discovery populates the CMDB, so it must be accurate.
Why It Breaks
Discovery tells you what exists. It doesn’t tell you if it matters, who owns it, if it’s complete, if it’s correct, or if it’s compliant.
Without active governance, your CMDB becomes a graveyard of stale, duplicate, and incomplete CIs. Teams stop trusting it. They build shadow spreadsheets. Your automation breaks. Change Management becomes guesswork.
When something goes wrong, MTTR skyrockets because responders waste time validating whether the CMDB data is even real.
What We Did Differently
At Atrinet, we stopped treating CMDB health as a cleanup project and started treating it as continuous governance – baked into operations, not bolted on afterward.
Instead of reacting to bad data, we leveraged ServiceNow’s full CMDB capabilities to build feedback loops that prevent it:
- Completeness & Correctness: Enforce required attributes using native health rules. Detect duplicates, orphans, and stale CIs. Auto-remediate or escalate
- Attestation & End-of-Life: Use Data Manager to ask CI owners regularly, “Does this exist? Do you own it?” Automate retire-archive-delete flows.
- Compliance & Reconciliation: Schedule certification cycles with CMDB Workspace policies. Define which data source wins when multiple sources conflict using CMDB 360.
- Query Builder & Remediation Rules: Create saved queries for impact analysis. Trigger workflows when health issues are detected using out-of-box remediation capabilities.
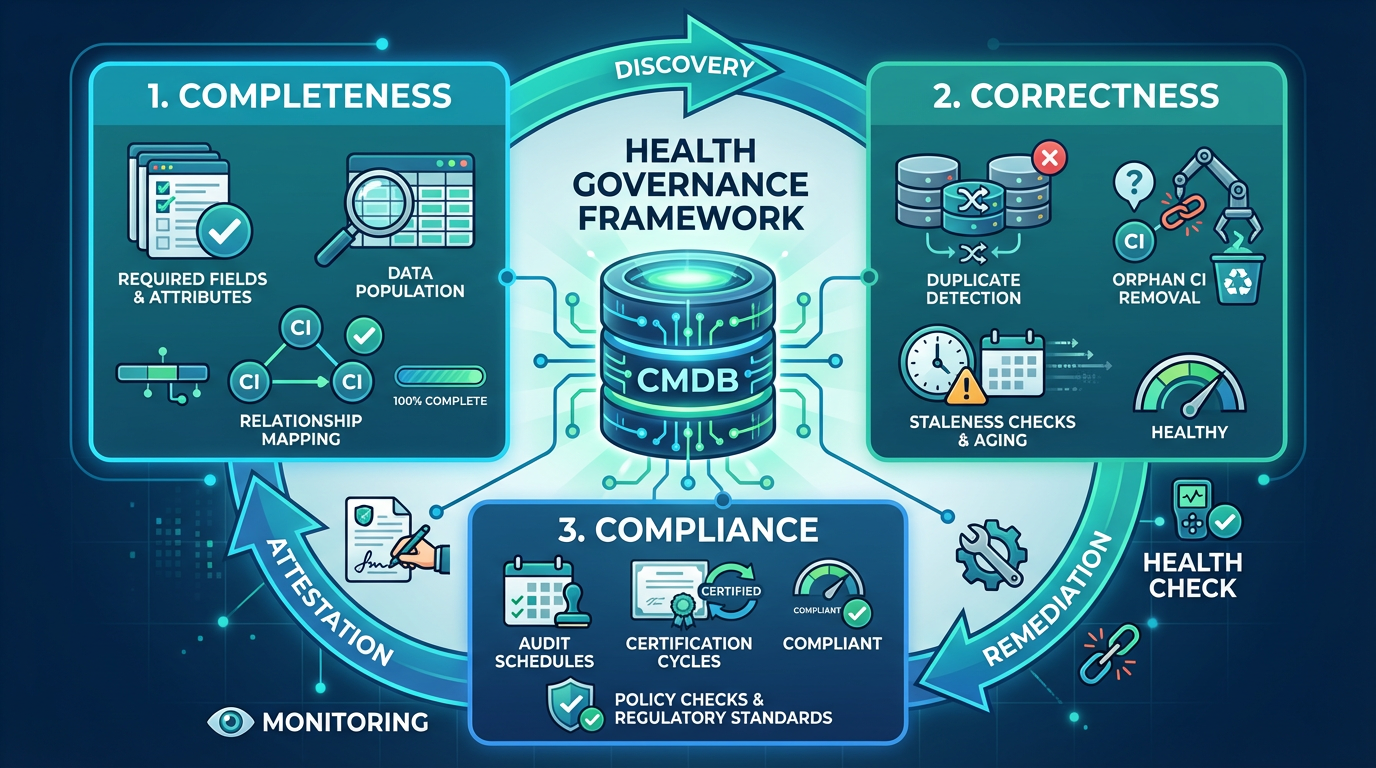
How It Works
Start with 2–3 critical services. Define required attributes, authoritative sources, and ownership. Enable ServiceNow’s native health features: completeness scores, correctness checks, compliance audits, and reconciliation rules. Build remediation flows that auto-create tasks or escalate to owners. Track completeness %, correctness issues, and MTTR improvement. Expand once proven.
Tradeoffs
This isn’t free. Initial setup takes 2–4 weeks. CI owners need to participate – if your org treats data quality as someone else’s problem, you’ll need exec sponsorship. Health rules need ongoing tuning.
But the alternative is worse: teams stop trusting the CMDB, build shadow systems, and you’re back to manual change impact analysis.
When to Use It
You need this if changes are failing due to bad CI data, MTTR is high because responders can’t trust dependency maps, audits find gaps, or teams are building Excel trackers.
If you’re using ServiceNow for Change, Incident, or Asset Management, this isn’t optional.
Here’s the truth nobody wants to say out loud: if you’re not actively governing your CMDB, you don’t have a CMDB – you have an expensive liability with a ServiceNow license.
We’ve seen organizations spend six figures on Discovery tools, hire CMDB admins, and still operate like it’s 2005 with spreadsheets and war rooms.
The problem isn’t the tool.
It’s the delusion that data quality happens by accident. It doesn’t. You either commit to treating your CMDB like the critical infrastructure it is – with ownership, accountability, and automation – or you admit it’s decorative and stop pretending it drives decisions. There’s no middle ground.
Half-maintained CMDBs are worse than no CMDB at all, because they give you false confidence right before everything breaks.
Key Takeaway
Discovery gives you data. Governance gives you trusted data. And trusted data is what lets you move fast without breaking things.
In Post 2, we’ll deep-dive into Data Manager (Attestation, End-of-Life & Certification), Completeness, Correctness, and Compliance – with real configurations, and gotchas from implementations we’ve run.
By: Sagie Ratzon
ITOM Expert, ServiceNow Implementation Specialist
LinkedIn